About me
I recently completed my PhD in the RLAI Lab at the University of Alberta, under the supervision of Dr. Martha White and Dr. Adam White. I am passionate about reinforcement learning (RL), with a primary research interest in offline learning, offline-to-online, and real-world applications.
Education
-
Doctor of Philosophy in Computing Science
Sept 2020 - May 2025Supervised by Dr. Martha White and Dr. Adam White
RLAI lab, University of Alberta
Thesis: Stable and Efficient Online Reinforcement Learning using Offline Data -
Master of Science in Computing Science
Sept 2017 - Sept 2020Supervised by Dr. Adam White and Dr. Martha White
RLAI lab, University of Alberta
Thesis: Emergent Representations in Reinforcement Learning and Their Properties -
Bachelor of Science with Honors in Computing Science
Sept 2013 - June 2017University of Alberta
Graduated with first class honors
Work History
-
Research Scientist
Nov 2025 - NowDeeproute.ai Ltd.
-
Visiting Scholar
June 2025 - Sept 2025Reinforcement learning for large language model reasoning
The Hong Kong University of Science and Technology (Guangzhou) -
Intern
Nov 2023 - Nov 2024Reinforcement learning for a real-world water treatment system
RL Core
Publications
* denotes equal contribution
-
Fat-to-Thin Policy Optimization: Offline Reinforcement Learning with Sparse Policies
ICLR, 2025Lingwei Zhu*, Han Wang*, Yukie Nagai
⮩ An offline RL algorithm learning a sparse policy.
⮩ Click to see our code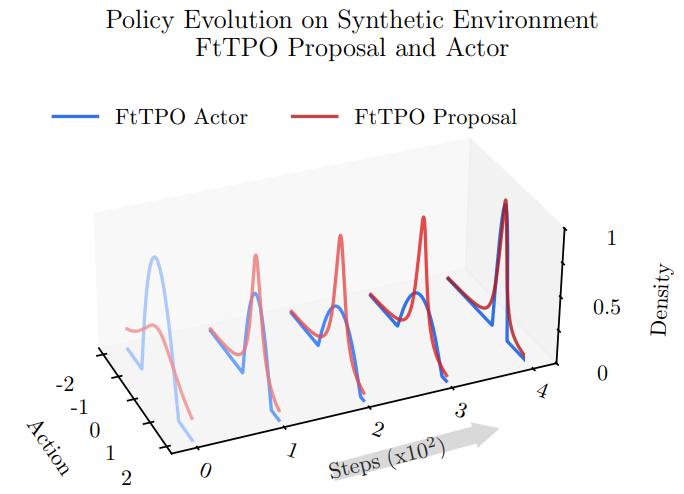
-
q-Exponential Family for Policy Optimization
ICLR, 2025Lingwei Zhu*, Haseeb Shah*, Han Wang*, Martha White
⮩ An investigation on policy parameterization.
⮩ Student's t-distribution is a strong candidate for drop-in replacement to the Gaussian.
⮩ Click to see our code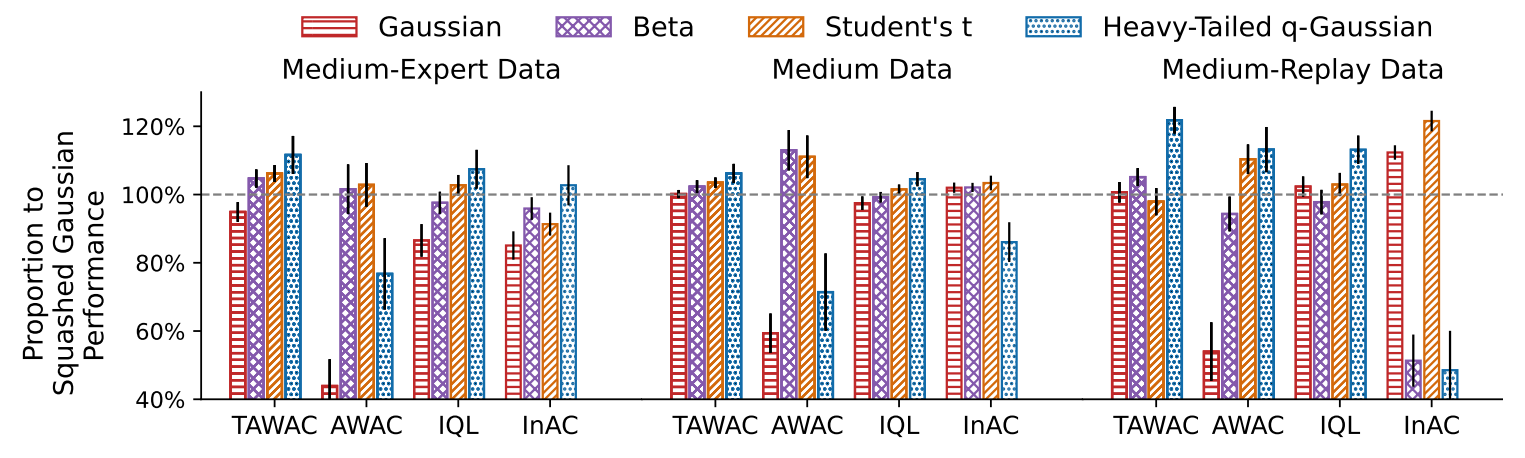
-
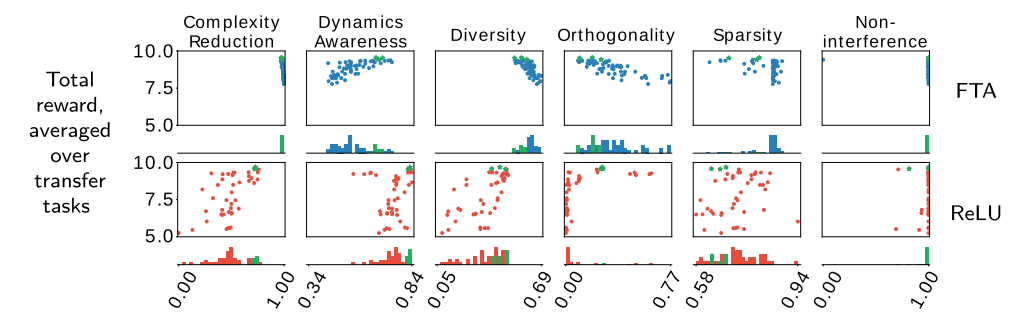
Investigating the Properties of Neural Network Representations in Reinforcement Learning
Artificial Intelligence, 2024Han Wang, Erfan Miahi, Martha White, Marlos C. Machado, Zaheer Abbas, Raksha Kumaraswamy, Vincent Liu, Adam White
⮩ A systematic approach to better understand why some representations work better for transfer.
⮩ Click to see our code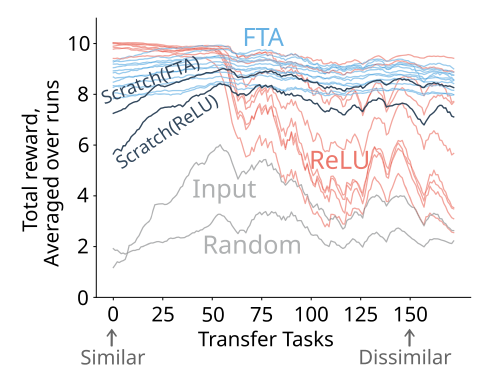
-
A Simple Mixture Policy Parameterization for Improving Sample Efficiency of CVaR Optimization
Reinforcement Learning Journal, 2024Yudong Luo, Yangchen Pan, Han Wang, Philip Torr, Pascal Poupart
-
Exploiting the Replay Memory Before Exploring the Environment: Enhancing Reinforcement Learning Through Empirical MDP Iteration
NeurIPS, 2024Hongming Zhang, Chenjun Xiao, Chao Gao, Han Wang, Bo Xu, Martin Müller
-
Offline Reinforcement Learning via Tsallis Regularization
Transactions on Machine Learning Research, 2024Lingwei Zhu, Matthew Kyle Schlegel, Han Wang, Martha White
-
The In-Sample Softmax for Offline Reinforcement Learning
ICLR, 2023, oralChenjun Xiao*, Han Wang*, Yangchen Pan, Adam White, Martha White
⮩ InAC: An offline RL method using in-sample softmax to learn good policy under insufficient action-coverage.
⮩ Click to see our code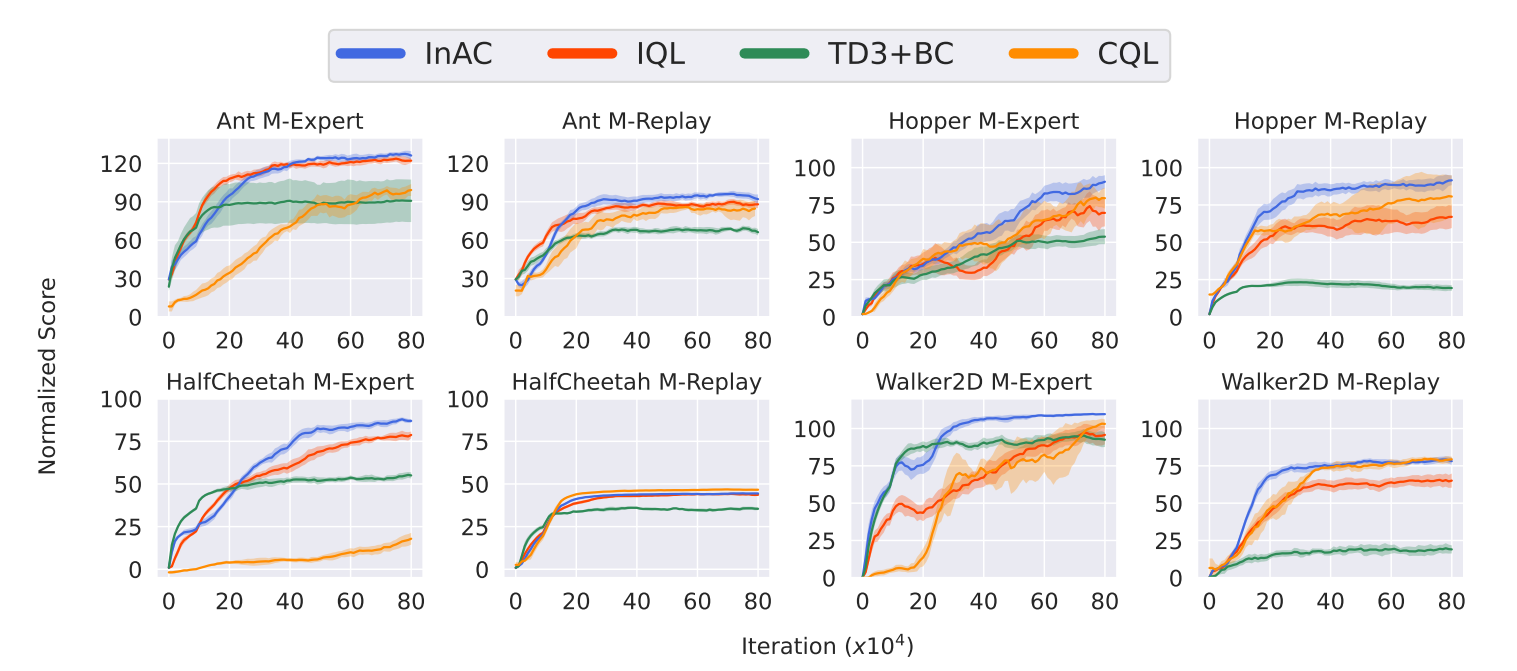
-
Measuring and Mitigating Interference in Reinforcement Learning
CoLLAs, 2023Vincent Liu, Han Wang, Ruo Yu Tao, Khurram Javed, Adam White, Martha White
-
Replay Memory as An Empirical MDP: Combining Conservative Estimation with Experience Replay
ICLR, 2023Hongming Zhang, Chenjun Xiao, Han Wang, Jun Jin, Bo Xu, Martin Müller
-
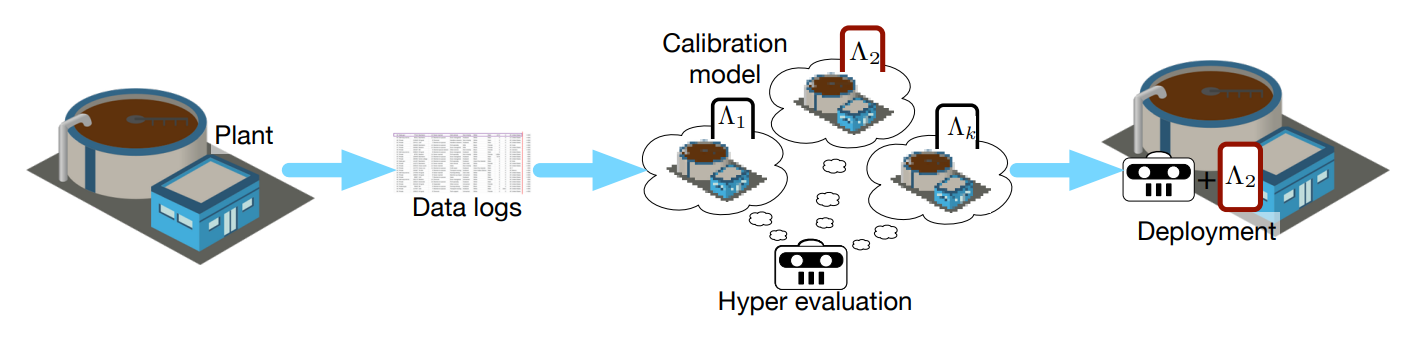
No More Pesky Hyperparameters: Offline Hyperparameter Tuning for RL
Transactions on Machine Learning Research, 2022Han Wang*, Archit Sakhadeo*, Adam White, James Bell, Vincent Liu, Xutong Zhao, Puer Liu, Tadashi Kozuno, Alona Fyshe, Martha White
⮩ Hyperparameter tuning from offline data, to fully specify the hyperparameters for an RL agent that learns online in the real world
Workshop Paper
-
Dynamics Models for Offline Hyperparameter Selection in Water Treatment
Jordan Coblin, Han Wang, Martha White, Adam White
Preprints
* denotes equal contribution
-
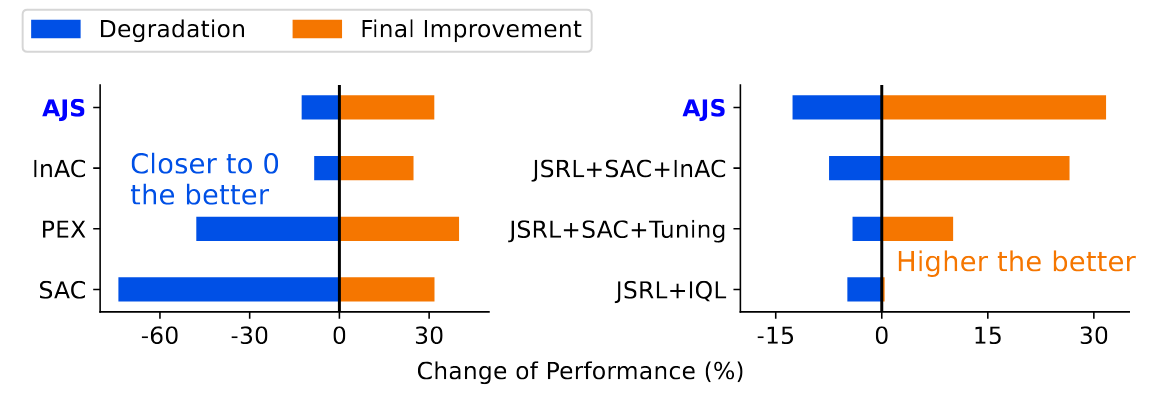
Fine-Tuning without Performance Degradation
Under ReviewHan Wang, Adam White, Martha White
⮩ A practical fine-tuning algorithm that gradually allows more exploration based on online estimates of performance.